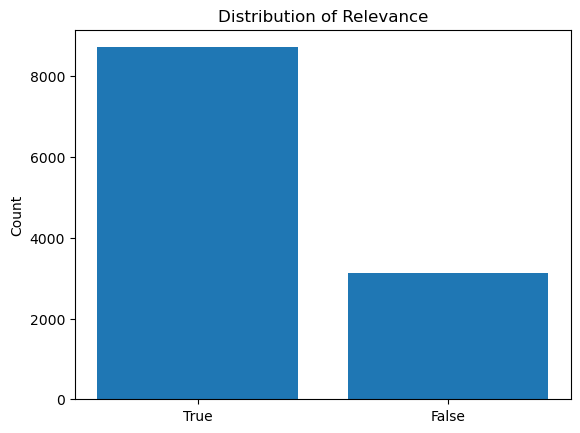
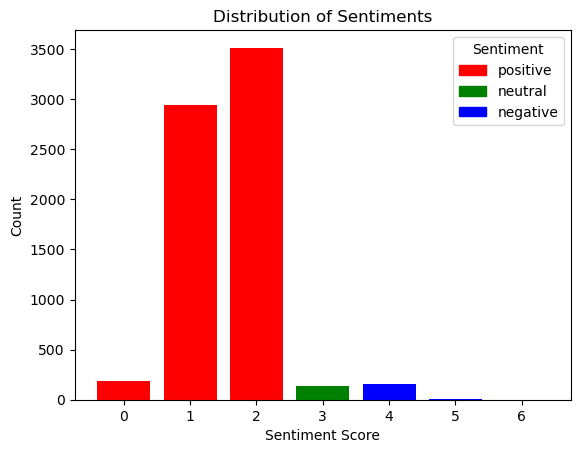
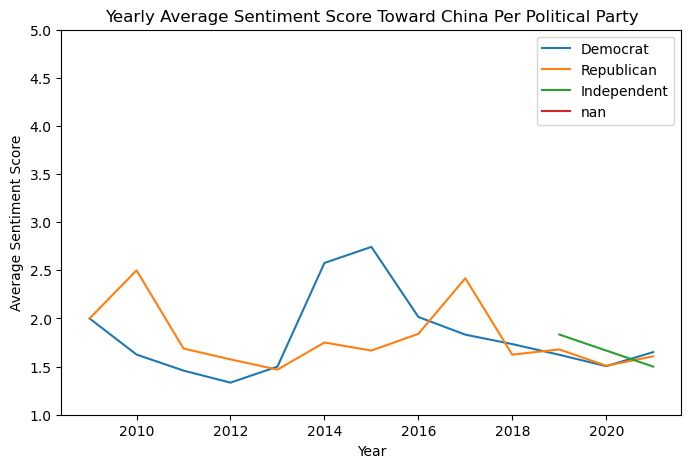
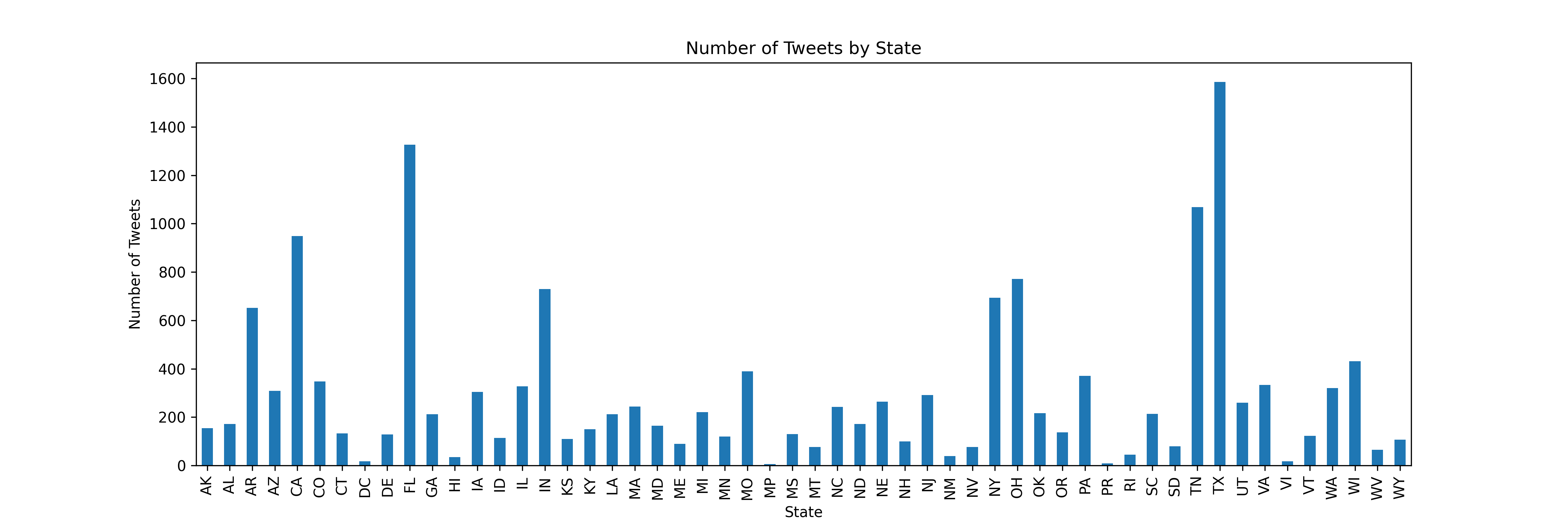
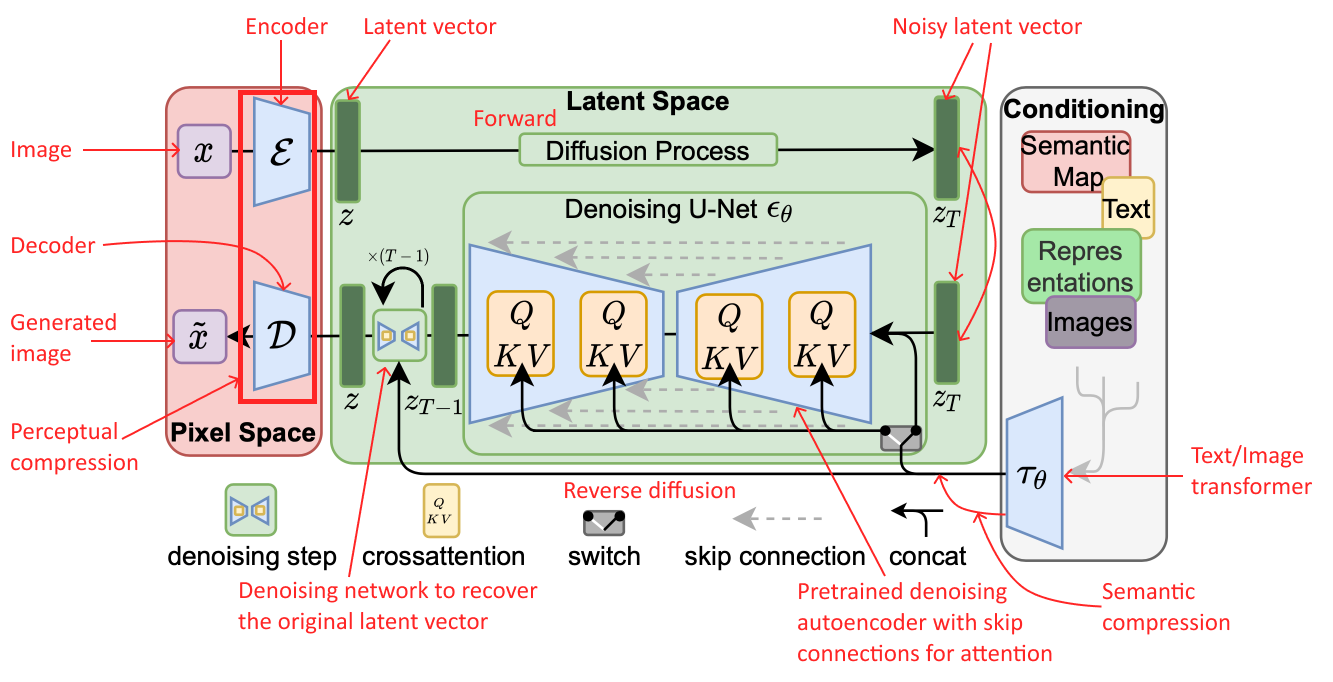
Background
Diffusion Model
Image generators like Dall-E, Google's Imagen, Stable Diffusion, and Midjourney use diffusion models to perform formerly manual tasks like image creation, denoising, inpainting, and outpainting. The diffusion method consists of a forward diffusion process and a reverse process. The goal of the model is to iteratively reverse the diffusion by predicting the Gaussian noise added at each time step.
Stable Diffusion
Stable Diffusion is an open-source diffusion model that generates images from text prompts.It consists of 2 stages:
- Latent Diffusion Model (LDM): The LDM learns to predict and remove noise in the latent space by reversing a forward diffusion process.
- Variational Autoencoder (VAE): The VAE converts data between latent and image space.
Probe
We use probes to visualize the representation learned by the LDM. A probe is a linear neural network that takes in the internal representation (i.e. intermediate activations) of an LDM and outputs a predicted image showing a certain property, such as depth, saliency, or shading. We quantify the performance of a probe by measuring the Dice Coefficient or Rank Correlation between the prediction and the label images.
Data
LDM Generated Image Dataset
Our diffusion image dataset consists of 617 images (512 pixels x 512 pixels) generated using Stable Diffusion v1.4. We have a CSV file that contains the prompt index, text prompt, and seed for each image. For example, the image with the prompt index 5246271, the text prompt "ZIGGY - EASY ARMCHAIR", and the seed 64140790 generated this 512 by 512 image.

(top right) Salient object detection mask generated by TRACER.
(bottom left) Depth map generated by MiDaS.
(bottom right) Shading and illumination map generated by Intrinsic.
Generate Image Labels With TRACER, MiDaS, and Intrinsic
- For salient object detection, we apply the salient object tracing model TRACER to generate a mask for each image. The masks are black and white, where white indicates the salient object, or foreground, and black indicates the background.
- For depth labels, we apply the pre-trained MiDaS model to the diffusion images to estimate their relative inverse depth maps.
- For shading labels, we apply the pre-trained Intrinsic model to the diffusion images to generate highly accurate intrinsic decompositions and estimate the shading maps.
Internal Representation Methods
Internal representation = the neural network’s self-attention layer’s intermediate activation output.
-

Data
Generate Images Using Stable Diffusion
We use the open-source code provided by Stable Diffusion to generate images that are 512 pixels by 512 pixels. Each image requires a prompt and a seed. The prompt describes what the image should portray while the seed ensures that we will generate the same image each time for the same prompt.
-

Get Ground Truths
Tracer, MiDaS, and Intrinsic
The diffusion images we generate using Stable Diffusion v1.4 do not have ground truth labels for salient object detection, depth, or shading, so we apply off-the-shelf models to those images to synthesize the ground truth images. The labels are the same size as the diffusion images.
-
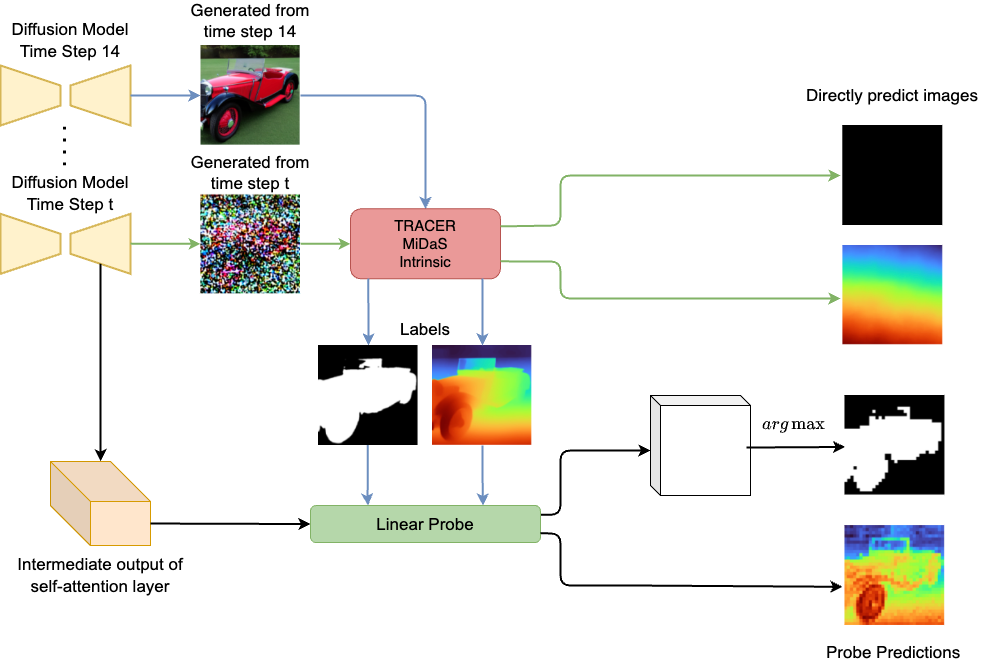
Training Probes
To Output 3D Properties
We train the probe to predict what the mask, depth map, or shading should look like based on the internal representation (self-attention layer output) at time step t. A different probe is trained for each block type, block, layer, and time step.
-

Choosing the Best Probe
The probes are trained on different U-Net blocks and layers and have varying performances because of their difference in location, number of features, and output size. We choose the probe trained on Decoder 4 layer 1 because it produces the biggest outputs and achieves the highest performance metrics.
-

Visualize the Diffusion Process
Comparing probing results with off-the-shelf model outputs
Apply the best probes for depth, salient object detection, and shading to a Stable Diffusion image's internal representation at each time step. Also apply MiDaS for depth, TRACER for salient object detection, and Intrinsic for shading to the intermediate images in the denoising process. See the comparison in the Results section.
Internal Representation Results
Probing the LDM
Using intermediate activations of noisy input images, linear probes can accurately predict
the foreground, depth, and shading. All three properties emerge early in the denoising process
(around step 3 out of 15), suggesting that the spatial layout of the generated image is determined
at the very beginning of the generative process.
| Foreground segmentation Dice coefficient | 0.85 |
|---|---|
| Depth estimation Rank Correlation | 0.71 |
| Shading estimation Rank Correlation | 0.62 |
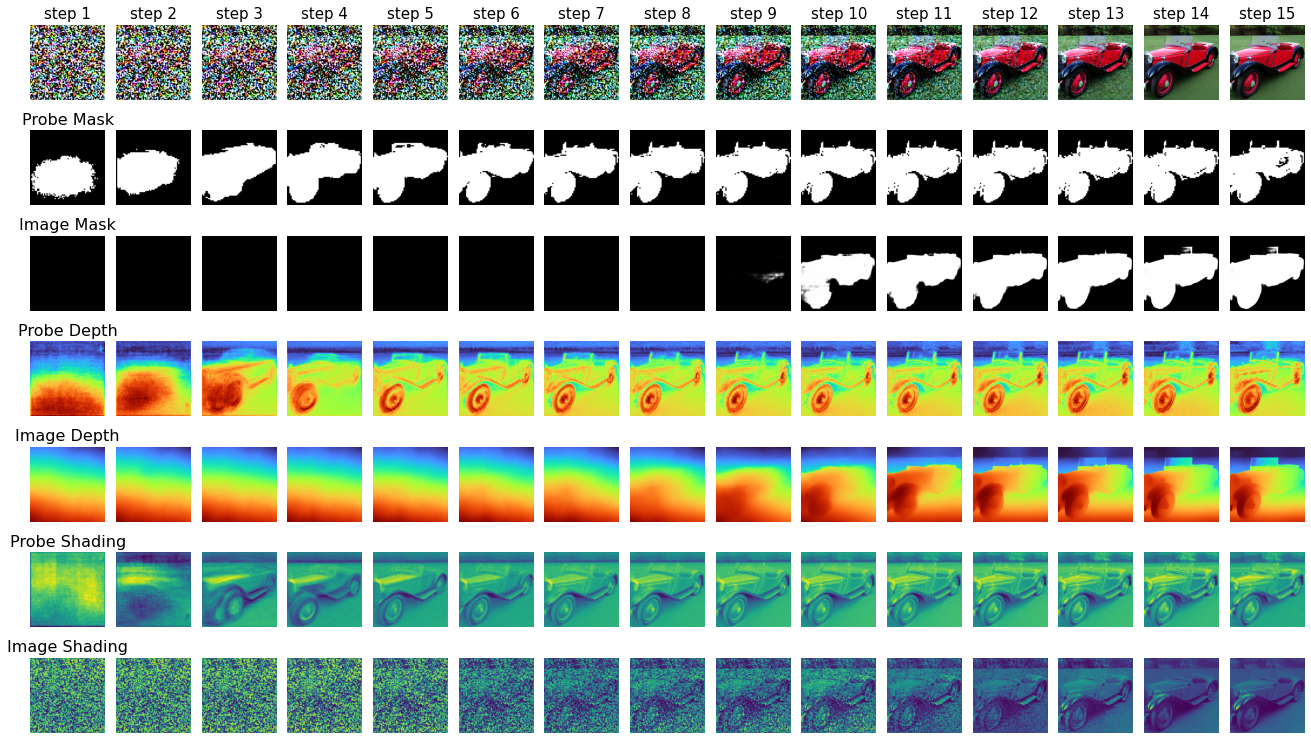
Image Classification Methods
-
Data
Generate Images Using Stable Diffusion
We use the open-source code provided by Stable Diffusion to generate images using prompts that match the ImageNet categories. For example, generating an image of a "tabby cat" or "lemons".
-
Apply the Model
VGG-16
VGG-16 is a convolutional neural network that is trained on a subset of the ImageNet dataset. It is able to classify images into 1000 categories. We run each intermediate image (at each timestep of the diffusion process) through VGG-16 to get a classification.
-
Plot Results
Explore Predictions and Plot Results
We plot the top five predictions at each timestep against the model's corresponding confidence on that specific prediction. This reveals some interesting findings about at what timestep the model starts to correctly classify the images and some commonalities in classification.
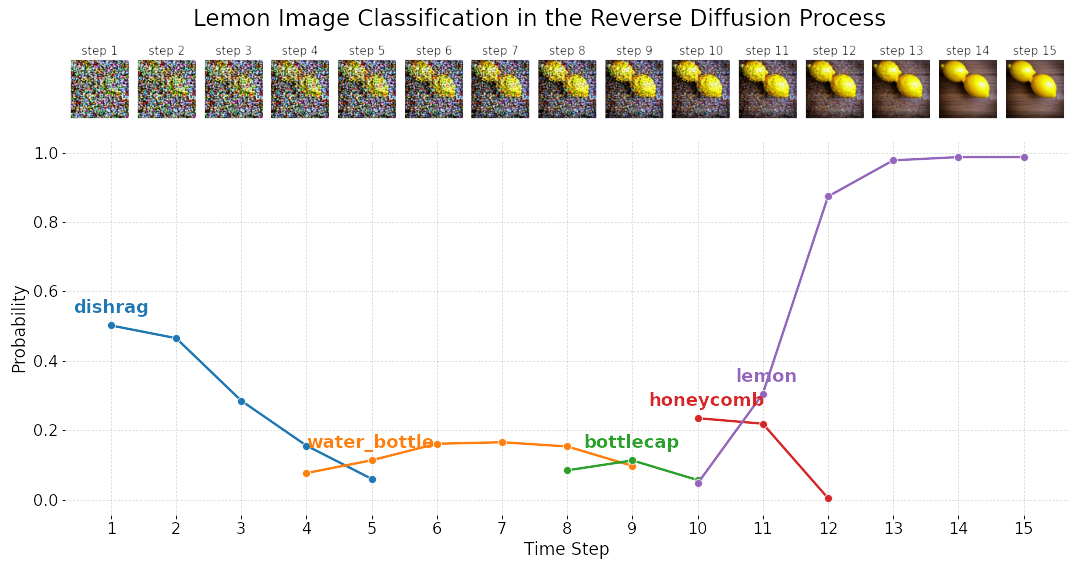
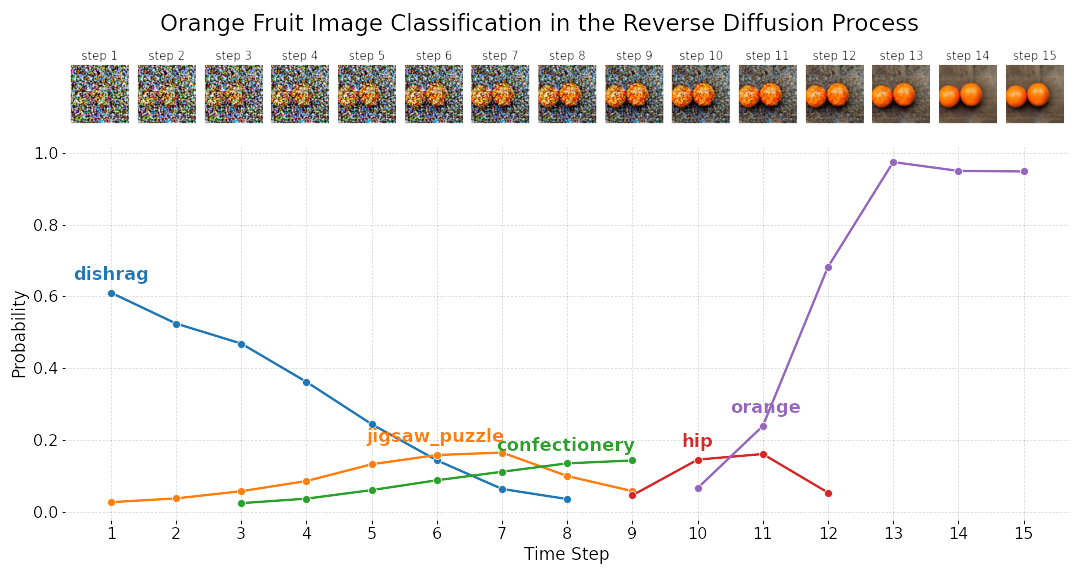
Image Classification Results
Comparing Real and Generated Image Classifications
Generated images: two lemons (98.75%), two oranges (94.8%)
Real images: singular lemon (87.7%), two lemons (99.4%), singular orange (87.0%)
Classifications Throughout the Diffusion Process
VGG-16 could not correctly identify the object until after step 11, which shows that saliency appears much later in the intermediate images. In contrast, saliency and other 3D information appear as early as step 3 out of 15 in an LDM's internal representation.
The correct classification has high confidence (> 90%) towards the end of the diffusion process for the majority of generated images.
This means that the generated images are fairly good representations of the object prompted.
Future Work
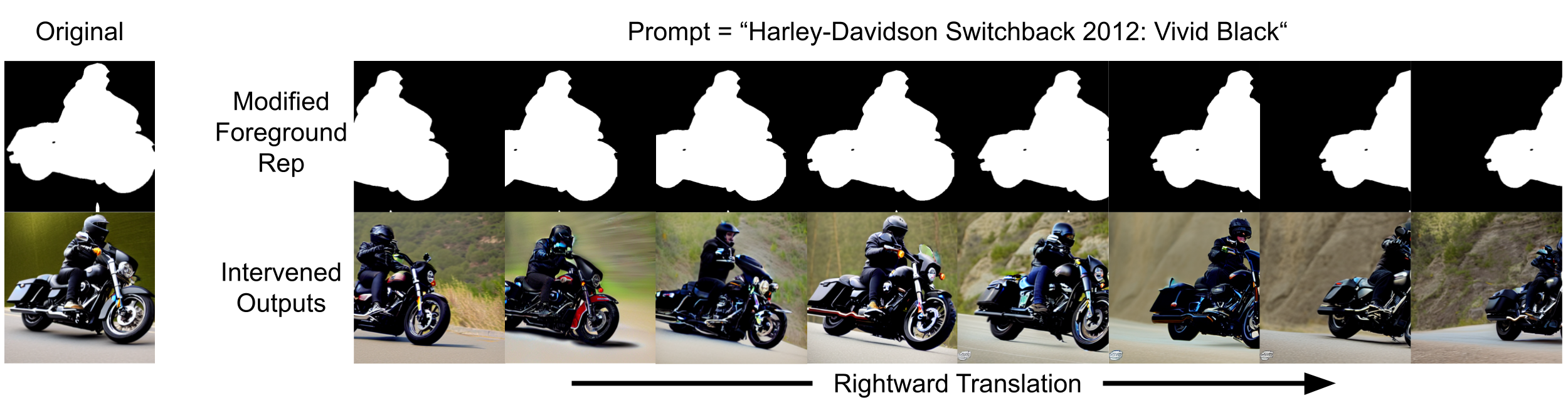
Intervening the LDM
In the paper by Y. Chen et al., they investigate intervening and modifying the internal representations
in order to reposition the salient object. This would be an interesting result to replicate, build upon, and
also compare to the depth-to-image capability of Stable Diffusion v2.0. It has implications for making image
generation even more customizable and realistic, as the generated image can be tailored to users' needs.
They find that the foreground mask has a causal role in image generation. Without changing the prompt, input latent
vector, and model weights, the scene layout of generated image can be modified by editing the
foreground mask.
Speeding Up Diffusion
If the bulk of the information is already encoded by very early steps in the denoising process, we can potentially speed up the rest of the steps without sacrificing quality. This brings in enormous cost savings, as training top-of-the line diffusion models like Stable Diffusion can cost hundreds of thousands of dollars, if not more.
Augmenting Datasets
When it comes to autonomous vehicles, where safety and accuracy are paramount, the need for diverse and comprehensive
datasets is critical. One way to enhance these datasets is by leveraging encoded depth information through diffusion models.
Usually, depth information is captured using a LiDAR sensor or depth cameras. However, collecting such information
can be resource intensive, and existing images may not have these pieces of information.
Diffusion models can help here in two ways. Synthetic depth maps that closely resemble real-world scenarios can be
generated, and potentially filling in depth information for existing images or images without complete depth maps.